
In einer Zeit, in der Cloud-Services, SDN und Infrastructure-as-Code zentrale Rollen in der IT spielen,
wirken klassische Netzwerkgrundlagen manchmal wie ein Überbleibsel aus früheren Tagen.
Viele Berufseinsteiger starten direkt in abstrakten Schichten: virtuelle Netzwerke, Policies, Automatisierung,
Containerplattformen und orchestrierte Umgebungen.
Doch unter all diesen modernen Technologien arbeiten nach wie vor die gleichen fundamentalen Prinzipien,
die seit Jahrzehnten das Rückgrat der digitalen Kommunikation bilden.
Dieser Artikel möchte eine Brücke schlagen zwischen der heutigen Abstraktionswelt und den Grundlagen,
auf denen alles steht – ohne Vorwürfe, sondern als Einladung, das technische Fundament wieder bewusster wahrzunehmen.
Warum Layer 1–3 heute wichtiger sind als je zuvor
Der klassische Netzwerkstack mag unsichtbar wirken, aber er bestimmt immer noch direkt,
wie moderne Plattformen und Cloud-Dienste funktionieren.
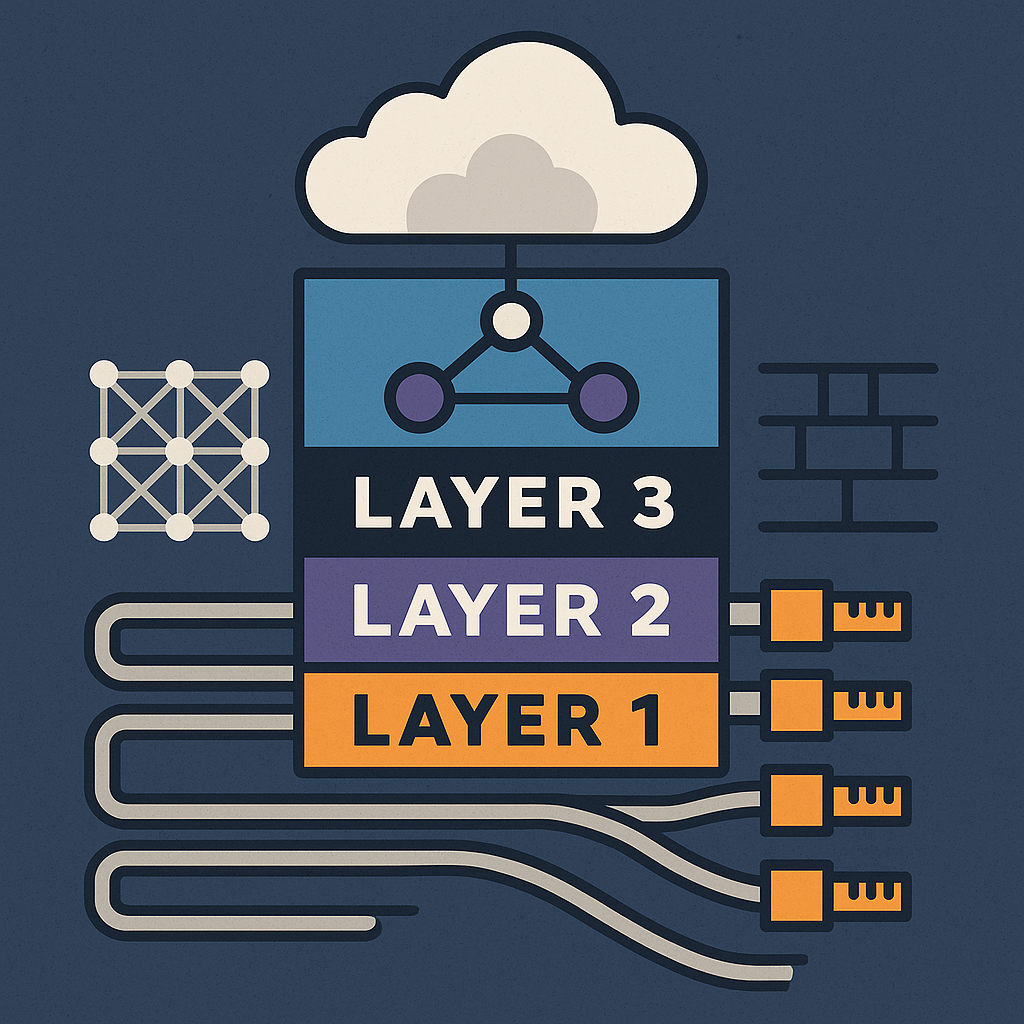
Layer 1 – Die physische Basis
- Kabellängen, Dämpfung, Signalverlust
- Glasfaser, DWDM, optische Module
- Störungen, Dämpfungsreserven, Quality Level
Layer 2 – Die Verbindungslogik
- Switching, MAC-Tabellen
- VLANs, MTU, Trunks
- Spanning Tree, Loop Prevention
Layer 3 – Die Netzwerkintelligenz
- Routing und Subnetting
- BGP, OSPF, ECMP
- Latenz, Jitter, Pfadwahl
Diese Grundlagen scheinen im Cloud-Alltag weit weg, doch sie bestimmen direkt die Funktionsfähigkeit von SDN, Kubernetes, VPNs,
Microservices und modernen WAN-Konzepten.
Wer die Zusammenhänge kennt, versteht schneller, warum ein Dienst instabil wird, warum Routing springt oder warum Cloud-Netze sich „unvorhersehbar“ verhalten.
Abstraktion hilft – aber sie verbirgt auch die Ursachen
Moderne Tools nehmen viel Arbeit ab: virtuelle Netzwerke entstehen per Klick,
Firewallregeln replizieren sich automatisch, SDN orchestriert komplette Umgebungen.
Doch die Abstraktion birgt eine Gefahr:
Man verliert das Verständnis dafür, warum ein System eigentlich funktioniert.
Ein Beispiel: Ein Ping-Durchschnitt von 30 ms wirkt harmlos.
Nur wer die Min- und Max-Werte betrachtet, erkennt, dass starke Schwankungen – Jitter – echte Auswirkungen auf VoIP, VPN und SD-WAN haben können. Ohne Grundwissen bleibt ein solches Problem unsichtbar.
Viele Ausbildungen vermitteln heute hauptsächlich den Umgang mit Tools und Oberflächen, aber kaum noch das tiefere Verständnis für Paketverhalten, Routinglogik oder physikalische Limitierungen. Diese Lücke fällt erst auf, wenn etwas nicht so funktioniert wie „automatisch vorgesehen“.
Was echte Senior-Kompetenz ausmacht
Senior-Level entsteht nicht durch die Anzahl der Cloud-Abos, Skripte oder YAML-Files,
die man bedienen kann. Sondern durch Wissen darüber, wie Datenpakete wandern, wie Protokolle reagieren und wie Netzwerkpfade wirklich arbeiten.
Wer die Grundlagen beherrscht, versteht:
- warum ein VPN bei 20 ms Jitter instabil wird,
- warum ein Backup-Fenster Routing-Spikes erzeugt,
- warum SD-WAN bei minimalen Latenzänderungen Pfade wechselt,
- weshalb MTU-Probleme Cloud-Dienste „zufällig“ ausbremsen,
- warum DNS-Latenz Microservices zum Stillstand bringen kann.
Solches Wissen entsteht nicht automatisch, nur weil moderne Tools funktionieren. Es entsteht durch Neugier, Praxis und das bewusste Beschäftigen mit den Grundlagen.
Cloud & SDN brauchen mehr Grundlagen – nicht weniger
Weit verbreitet ist die Annahme, dass Cloud-Plattformen klassische Netzwerktechnik überflüssig machen. Doch die Realität ist umgekehrt:
Je höher die Abstraktion, desto empfindlicher sind die Systeme gegenüber Problemen auf den unteren Schichten.
Die Cloud kann abstrahieren – aber sie kann Layer 1–3 nicht aufheben.
Deshalb werden Menschen, die beides verstehen – moderne Werkzeuge und klassische Netzprinzipien –
in Zukunft noch wertvoller werden.
Fazit: Grundlagen studieren, um wirklich Senior zu werden
Dieser Artikel soll keine Kritik sein, sondern eine Ermutigung. Wer die Grundlagen beherrscht, kann moderne Technologien besser einordnen, tiefere Zusammenhänge erkennen und Probleme wirklich lösen – statt Symptome zu verwalten.
Die Wahrheit ist einfach:
Die Branche lehrt Netzwerkgrundlagen heute seltener. Wer wirklich Senior-Level erreichen möchte, muss vieles davon selbst erlernen, ausprobieren und bewusst studieren – unabhängig davon, wie stark Cloud und SDN abstrahieren.
Die gute Nachricht:
Wer diesen Weg geht, versteht nicht nur das Fundament besser, sondern auch die moderne IT.
Und genau dieses Zusammenspiel macht aus einem Administrator einen echten Engineer.